
Czas odtworzenia usług po awarii decyduje o tym, czy firma wraca do pracy po kilkunastu minutach, czy dopiero wtedy, gdy straty są już poważne. W tym tekście rozkładam temat RTO na części: wyjaśniam definicję, pokazuję różnice względem RPO i MTD, a potem przechodzę do tego, jak ustala się sensowną wartość dla systemów i procesów biznesowych. To szczególnie ważne w cyberbezpieczeństwie, bo po ransomware, awarii infrastruktury albo błędzie wdrożeniowym sam backup nie rozwiązuje problemu.
Najkrócej o czasie odtworzenia usług po awarii
- RTO określa maksymalny akceptowalny czas niedostępności usługi po incydencie.
- Im niższe RTO, tym droższe i bardziej złożone muszą być mechanizmy odtwarzania.
- RTO nie jest tym samym co RPO, MTD ani MAO, choć te wskaźniki są ze sobą powiązane.
- W praktyce wyznacza się je po analizie wpływu na biznes, a nie na podstawie intuicji administratora.
- Same kopie zapasowe nie skracają RTO, jeśli nie ma przetestowanego procesu odtworzenia.
Najkrócej o czasie, po którym przestój staje się zbyt drogi
Ja patrzę na RTO przede wszystkim jak na granicę biznesowej cierpliwości. To maksymalny czas, w którym system, usługa albo proces może być niedostępny po incydencie, zanim przestój zacznie powodować nieakceptowalne skutki operacyjne, finansowe albo reputacyjne.
W terminologii NIST chodzi o czas, po którym zasób systemowy nie powinien już pozostawać w fazie odzyskiwania, bo zaczyna szkodzić misji organizacji. W praktyce nie mierzę więc „naprawy serwera”, tylko moment, w którym ludzie znowu mogą pracować, wystawiać faktury, przyjmować zamówienia albo rozliczać płatności. To właśnie dlatego ten wskaźnik jest tak ważny w planach ciągłości działania.
Jeśli firma jest w stanie obsłużyć ręcznie kilka godzin przerwy, RTO może być stosunkowo luźne. Jeśli każda minuta przestoju oznacza utracone transakcje lub zatrzymanie produkcji, granica musi być dużo ostrzejsza. Żeby dobrze ją ustalić, trzeba jednak rozdzielić RTO od pozostałych parametrów odzyskiwania.
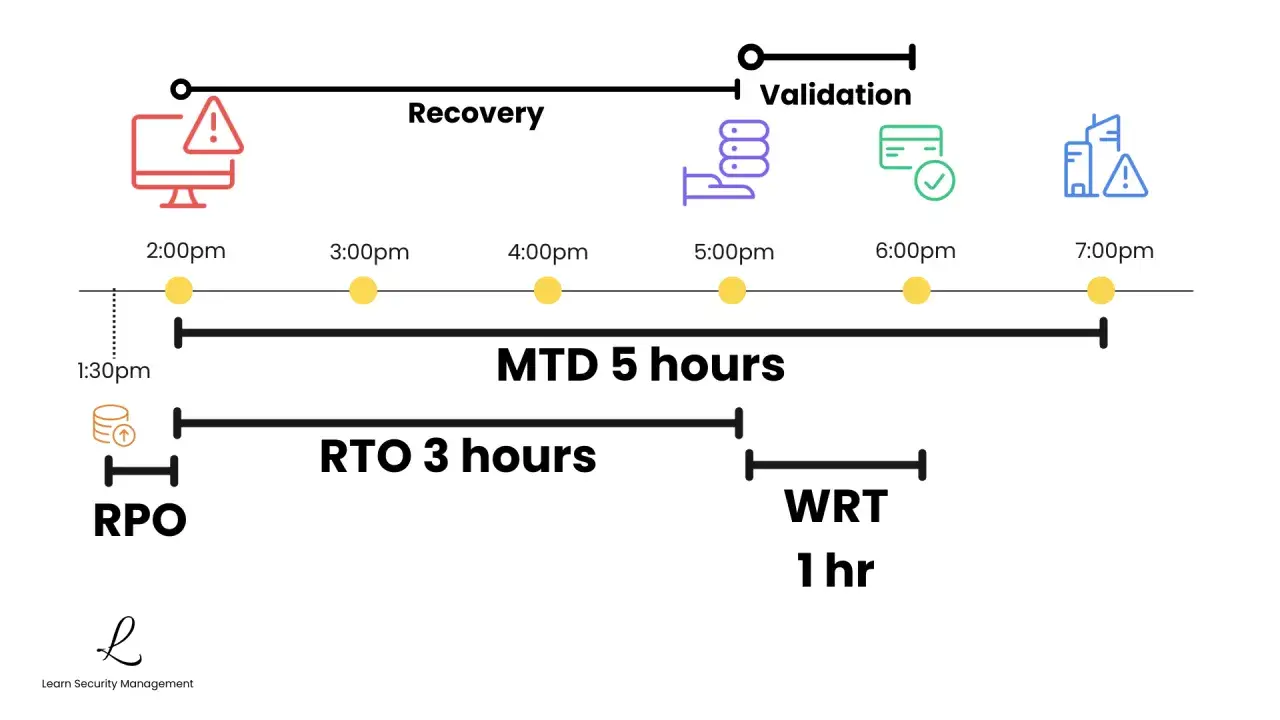
RTO, RPO i MTD nie opisują tego samego
Najwięcej nieporozumień bierze się stąd, że te skróty brzmią podobnie, ale odpowiadają na zupełnie inne pytania. W polskich materiałach spotkasz też MAO i MTPD, czyli miary maksymalnego akceptowalnego przestoju lub zakłócenia. To ważne, bo bez tej różnicy łatwo zaplanować ochronę danych, a zaniedbać czas odtworzenia usług.
| Skrót | Co mierzy | Na jakie pytanie odpowiada |
|---|---|---|
| RTO | Maksymalny czas przywrócenia usługi lub procesu po incydencie | Jak długo możemy nie działać, zanim zacznie się realna szkoda? |
| RPO | Maksymalny akceptowalny wiek danych, które trzeba odtworzyć | Ile danych możemy stracić bez krytycznych konsekwencji? |
| MTD / MTPD / MAO | Granica, po której skutki przerwy stają się nieakceptowalne | Kiedy przestój przestaje być do przyjęcia dla biznesu? |
Zależność jest prosta: RTO powinno zmieścić się przed MTD, bo inaczej odzyskujesz usługę za późno. NIST zwraca też uwagę, że przywracanie systemu może wymagać dodatkowego czasu na ponowne przetworzenie danych, więc sama techniczna dostępność nie wystarcza. Dopiero po takim rozdzieleniu można sensownie policzyć własną wartość dla firmy.
W praktyce patrzę na to jak na trzy różne warstwy decyzji: ile czasu możemy stać, ile danych możemy stracić i od kiedy szkoda staje się nie do zaakceptowania. Kiedy te granice są jasne, można przejść do wyznaczania konkretnej liczby dla własnej organizacji.
Jak wyznaczam RTO w oparciu o wpływ na biznes
RTO nie wyznacza się z brzucha. Zaczynam od BIA, czyli Business Impact Analysis, która pokazuje, jakie procesy przynoszą przychód, które obsługują klientów i gdzie godzina przestoju boli najbardziej. Bez tego łatwo przepłacić za nadmiarową architekturę albo, odwrotnie, ustawić zbyt optymistyczny cel, którego nikt nie umie dowieźć.
- Identyfikuję procesy i aplikacje krytyczne. Najpierw trzeba wiedzieć, co naprawdę musi działać: sprzedaż, płatności, logistyka, kadry, systemy produkcyjne czy obsługa klienta.
- Szacuję koszt jednej godziny przestoju. To nie tylko utracony przychód, ale też opóźnione faktury, kary SLA, praca ręczna i koszt komunikacji kryzysowej.
- Sprawdzam zależności. Jeden system rzadko działa sam. Potrafi zależeć od DNS, tożsamości, ERP, sieci, integracji z dostawcą albo zewnętrznego operatora płatności.
- Ocenam obejścia ręczne. Jeśli proces da się przez kilka godzin prowadzić manualnie, RTO może być mniej agresywne. Jeśli nie, cel musi być ostrzejszy.
- Potwierdzam wszystko testem odtworzeniowym. Bez testu deklaracja jest tylko deklaracją, a nie realnym parametrem odzyskiwania.
Praktyczny przykład wygląda bardzo zwyczajnie: jeśli platforma sprzedażowa generuje średnio 12 000 zł przychodu na godzinę, a pełne odtworzenie zajmuje 6 godzin, to potencjalna strata z samego przestoju wynosi 72 000 zł, zanim doliczysz reklamacje, karne SLA i obsługę kryzysową. Właśnie dlatego RTO jest decyzją biznesową, a nie tylko technicznym parametrem.
Sama decyzja nie wystarczy jednak bez architektury i procedur, które faktycznie dowiozą taki czas. I tu pojawia się pytanie, co naprawdę skraca odzyskiwanie po incydencie.
Co realnie skraca odtwarzanie po incydencie
Największą różnicę robi nie pojedynczy backup, lecz cały łańcuch odzyskiwania. CISA podkreśla, że kopie zapasowe trzeba regularnie testować, bo dopiero wtedy widać, czy odtworzenie działa w praktyce, a nie tylko w dokumentacji. To ważne zwłaszcza po atakach ransomware, kiedy okazuje się, że backup istnieje, ale nikt nie sprawdził, czy da się z niego szybko wrócić do pracy.
| Model odtwarzania | Wpływ na RTO | Koszt i kompromis |
|---|---|---|
| Active-active | Minuty lub niemal zero | Najwyższy koszt, największa złożoność, ale też najszybszy powrót do pracy |
| Warm standby | Od kilkunastu minut do kilku godzin | Średni koszt, zwykle dobry kompromis dla usług krytycznych |
| Cold standby | Godziny lub dni | Najtańsze rozwiązanie, ale wolne i zależne od sprawnego odtwarzania środowiska |
- Replikacja danych skraca czas odtworzenia, ale nie zwalnia z testów spójności.
- Automatyczny failover ogranicza czas reakcji ludzi, ale wymaga stabilnej infrastruktury i dobrego monitoringu.
- Runbook, czyli instrukcja krok po kroku dla zespołu, zmniejsza chaos w trakcie incydentu.
- Immutable backup pomaga przetrwać ransomware, ale nadal trzeba umieć szybko odtworzyć system.
Kiedy ta warstwa działa, można przypisać konkretne wartości do usług o różnej krytyczności. I właśnie tutaj najłatwiej zobaczyć, że nie każda aplikacja wymaga tego samego poziomu ochrony.
Jakie poziomy mają sens dla różnych usług
Nie każda usługa musi mieć RTO liczone w minutach. Im niższa akceptowalna przerwa, tym większy koszt redundancji, testów i utrzymania. Dlatego patrzę na to przez pryzmat krytyczności, a nie przez jedną uniwersalną liczbę dla całej firmy.
| Usługa lub proces | Orientacyjny RTO | Dlaczego właśnie tyle |
|---|---|---|
| Archiwum dokumentów, środowiska testowe, intranet pomocniczy | 24-72 godziny | Przerwa jest uciążliwa, ale zwykle nie zatrzymuje kluczowych procesów biznesowych |
| Poczta, HR, DMS, raporty operacyjne | 4-24 godziny | Wpływ na pracę jest wyraźny, ale firma zwykle może działać częściowo ręcznie |
| CRM, ERP, service desk | 1-4 godziny | Tu już zaczyna się realny koszt przerwania obsługi klientów i operacji wewnętrznych |
| E-commerce, płatności, integracje B2B | 15-60 minut | Każda dłuższa przerwa przekłada się na utracone transakcje i efekt domina w procesach |
| Systemy produkcyjne OT, core transakcyjne | 0-15 minut lub niemal natychmiast | Tu przestój bywa bardzo kosztowny albo wręcz niebezpieczny dla ciągłości działania |
To nie są normy sztywne, tylko praktyczne widełki, które pomagają myśleć o kosztach i priorytetach. W realnym projekcie najszybciej rośnie nie koszt samego backupu, ale koszt utrzymania całego ekosystemu: dostawcy, DNS, tożsamości, sieci, licencji i lokalizacji zapasowej. Im ostrzejsze RTO, tym bardziej złożona staje się operacja.
Prawdziwe problemy zaczynają się zwykle nie przy samej liczbie, tylko przy błędach w założeniach. I to właśnie one najczęściej psują sens całego parametru.
Najczęstsze błędy przy ustalaniu wartości
Najczęstszy błąd, który widzę, jest banalny: wartość wpisuje się do dokumentu, zanim ktoś policzy zależności i przetestuje odtworzenie. Na papierze wszystko wygląda dobrze, ale w dniu awarii okazuje się, że SSO nie wstaje, DNS nie propaguje zmian albo nikt nie ma dostępu do konta awaryjnego.
- Jedno RTO dla całej organizacji. To wygodne administracyjnie, ale biznesowo prawie zawsze zbyt uproszczone.
- Mylenie RTO z backupem. Częstotliwość kopii mówi o RPO, nie o tym, jak szybko wrócisz do pracy.
- Pomijanie zależności. System może działać na serwerze, ale i tak być bezużyteczny bez tożsamości, sieci albo integracji z partnerem.
- Wiara w ręczne obejścia. Czasem pomagają, ale nie mogą zastępować planu odtworzenia.
- Brak testów po zmianach. Każda większa migracja, aktualizacja lub zmiana architektury może zepsuć wcześniejsze założenia.
- Cel bez budżetu i właściciela. Jeśli nikt nie odpowiada za dowiezienie wyniku, wskaźnik zostaje tylko deklaracją.
W praktyce pomaga mi prosta zasada: jeśli po teście odtworzenie trwa 4 godziny, a cel mówi o 1 godzinie, to nie jest „małe odchylenie”, tylko sygnał, że trzeba poprawić proces albo architekturę. Właśnie dlatego ostatni krok polega na zamianie parametru w ćwiczony plan, a nie w zapis do folderu.
Jak zamienić wskaźnik w plan, który przejdzie test awarii
Jeśli chcę, żeby RTO działało w praktyce, spinam biznes, IT i bezpieczeństwo w jeden scenariusz odzyskiwania. Bez tego każdy zespół będzie miał własne wyobrażenie o „szybkim powrocie”, a awaria bezlitośnie pokaże, że te wyobrażenia nie są tym samym.
- Przypisuję właściciela biznesowego i technicznego dla każdej krytycznej usługi.
- Układam kolejność uruchamiania systemów, bo nie wszystko da się podnieść równolegle.
- Tworzę runbook, czyli instrukcję operacyjną z jasnymi krokami, kontaktami i progami eskalacji.
- Ćwiczę pełny scenariusz co najmniej raz do roku i po każdej większej zmianie architektury.
- Porównuję realny czas odtworzenia z celem i koryguję plan tam, gdzie różnica jest zbyt duża.
Dobre RTO nie jest liczbą z prezentacji. To granica, którą firma rzeczywiście potrafi obronić w dniu awarii, po ataku ransomware albo po błędzie wdrożenia. Jeśli po teście odtworzenia czas się nie spina, trzeba poprawić proces, architekturę albo oczekiwania biznesu, bo inaczej wskaźnik pozostaje tylko deklaracją.